实测 ChatGPT Work vs Claude Cowork,OpenAI 这次真追上来了
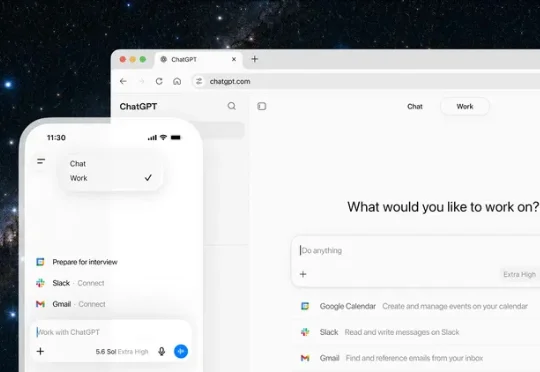
实测 ChatGPT Work vs Claude Cowork,OpenAI 这次真追上来了7 月 9 日,OpenAI 一口气发了三样东西,新模型 GPT-5.6,一个把 Chat、Work、Codex 装进同一个壳的新桌面应用,以及本文的主角 ChatGPT Work。官方的说法是,ChatGPT 从此不再只是回答问题,而是把活真正干完,交出来的不是聊天记录,是表格、文档、PPT,甚至一个能直接分享的网站。
来自主题: AI产品测评
8445 点击 2026-07-11 11:17